この記事の趣旨
2016年に発表された"An Experimental Comparison of Thirteen Relational Equi-Joins in Main Memory"という 論文を読みました。 様々な結合手法を包括的に比較した論文でどのような結合方法がどのような時に適しているかを示しています。
An Experimental Comparison of Thirteen Relational Equi-Joins in Main Memory
著者について
Stefan Schuh、Xiao Chen、Jens Dittrichのグループによる論文。 いずれもDBMSや分析システム、Hadoopなどにおける検索高速化・最適化の研究を行なっている。
問題意識
関係結合はほとんど全てのクエリプランにおいて中核をなす処理であり、定期的に研究・改良され再検討 されてきた。 新たな手法が提案され実験を行なわれるものの、それぞれ結果において比較を困難にする要素や 幾らかの矛盾を孕んでいた。
例えば同じハッシュベースの結合アルゴリズムの比較でも実装が異なったり、複数の論文でパフォーマンス比較で 正反対の結果を示しているためである。
そのため単純に論文執筆時点で最も高速な結合アルゴリズムを結論づけることが困難であった。
手法
本論文では結合方法を以下の3つに分類した 1. パーティションベースハッシュジョイン 結合対象となるリレーションをペアとなるキャッシュに収まる小さなパーティションに分割し結合する手法。 ハッシュテーブルの構築と結合されるデータの探索のキャッシュミスを最小にする事を目的としている。
非パーティションベースハッシュジョイン 1つのグローバルパーティションテーブルを構築しながら結合を行なう手法で、マルチスレッドと順番に依存しない 実行によりキャッシュミスのパフォーマンス劣化を隠蔽している。
ソートマージジョイン 結合対象となるリレーションを結合キーでソートし、結合を行なう手法。 ソートはSIMDによりベクトル化される。
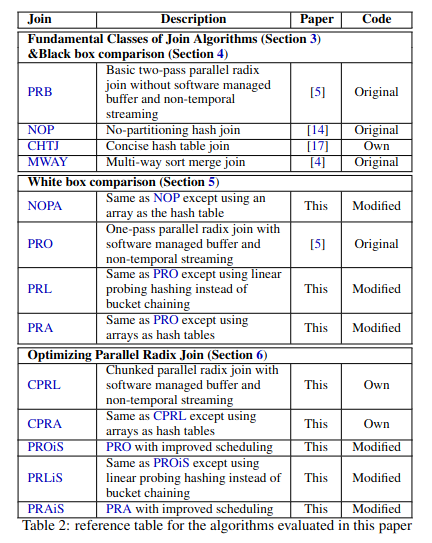
検証ではこれらの結合方法を以下の3つのテストで使用するために、全部で13のアルゴリズムを検証している。 1. ブラックボックス比較 基本となる3種4実装の結合方法をブラックボックス的に比較する。
ホワイトボックス比較 ブラックボックス比較で検証する結合方法に先行研究で示された最適化を施した上で比較を行なう。
パラレルラディックスジョイン比較 NUMAを考慮した結合におけるそれぞれのパフォーマンスを比較する。
結果
- パーティション結合の一種であるリモート書込みを排除したCPR系アルゴリズムは小さな入力に対して有効ではない
- スケールの大きい結合ではとくに理由が無い場合、パーティションベースのジョインを利用する
- 大きなサイズのページを利用する
- ソフトウェアライトコンバインバッファ()を利用する
- パーティションジョインでは適切なパーティションビットを利用する
- できるかぎりシンプルなアルゴリズムを利用する
- NUMAを考慮したアルゴリズムを利用する
- 実行時間とクエリ時間は同一ではない
作業時間
- read
- 31:34
- 31:34
- author
- 35:18
- 3:46
- summary
- 77:50
- 42:32