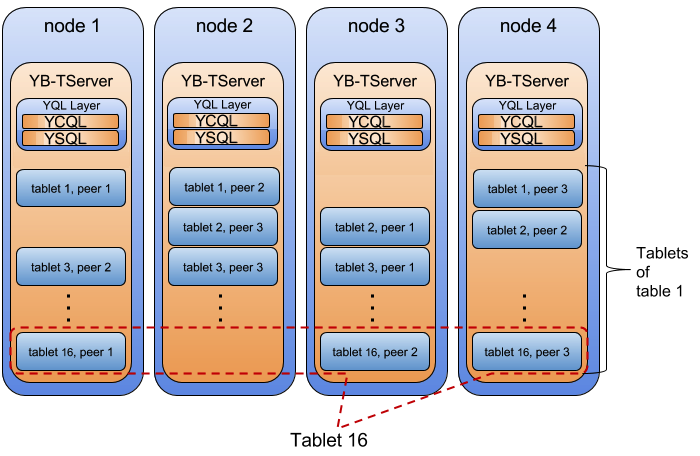
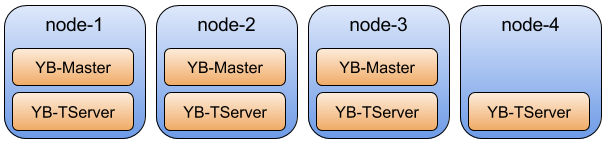
前回からつづいてYugabyteDBのドキュメントを読んでいきます。
前回はArchitecture > Key Concepts > YB-TServer serviceを読みました。 今回はArchitecture > Key Concepts > YB-Master serviceを読みます。
ドキュメントのバージョンは最新のv2.19 previewです。 また画像は同ドキュメントより引用しています。
YB-Master service
YB-Masterサービスはテーブルやそのタブレットの場所、ユーザー・ロールの権限といったシステムのメタデータとレコードの管理を行っている。
それに加えYB-Masterはロードバランシングやレプリケーションの開始といったバックグラウンドオペレーションの管理や、テーブルのCREATEや
ALTER、DROPといった様々な管理オペレーションの責任を持つ。
YB-MasterはRaft Groupを組むことで高可用性を実現し、またテーブルに対するI/Oの単一障害点にならない。
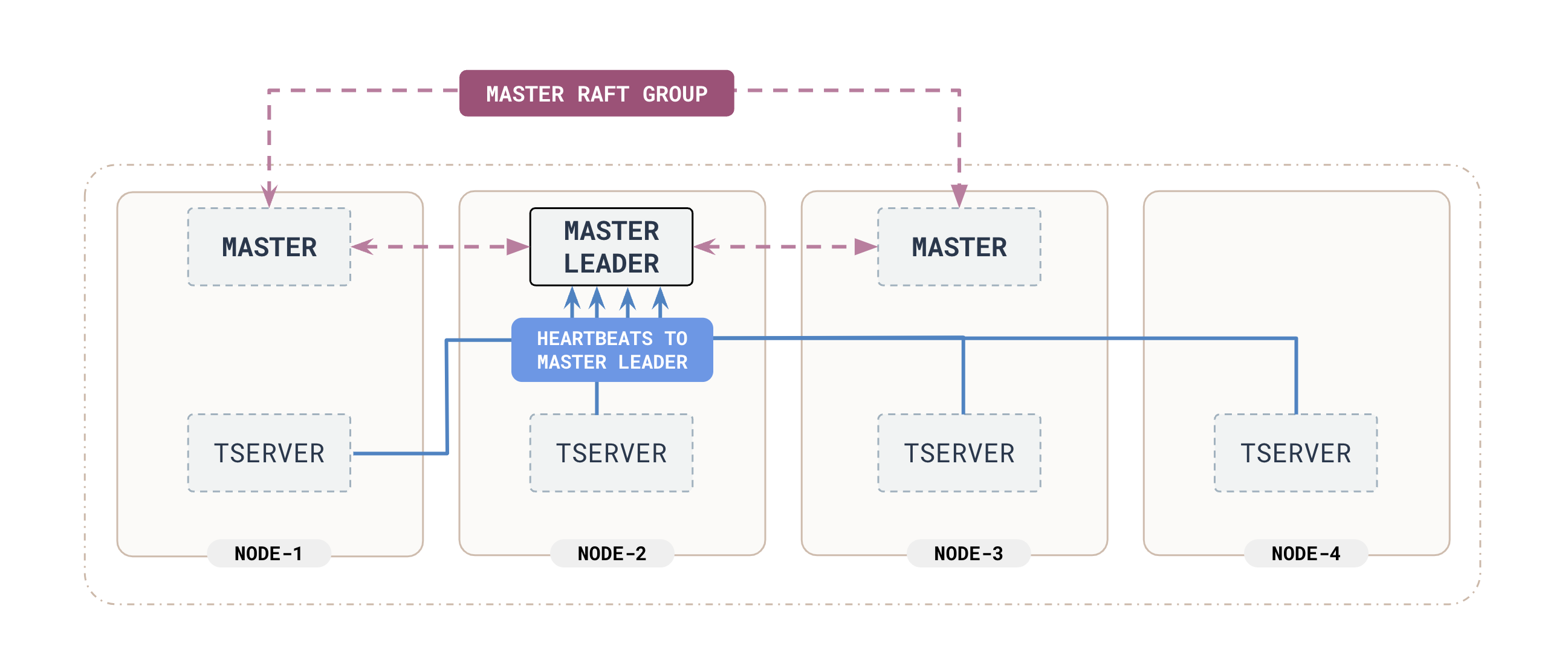
Functions of YB-Master
YB-Masterはシステムの重要な機能を複数持っている。
Coordination of universe-wide administrative operations
CREATE TABLEやALTER TABLE、DROP TABLEといったユーザーからのリクエスト処理やバックアップの実行などUniverseをまたぐ
オペレーション実行の調整を担当している。
YB-Masterではこれらのオペレーションがテーブルを保持するYB-TServerの状態に関わらず、全てのテーブルに伝搬されることを保証する。
YugabyteDBは分散システムのため、Universeをまたぐ処理中にYB-TServerに障害が発生し一部のタブレットへの適用に失敗してもオペレーションの 結果に問題が発生しないことが重要だからである。
Storage of system metadata
それぞれのYB-Masterではネームスペースやテーブル、ロール、パーミッション、YB-TServerへ割り当てたテーブル情報を含む システムメタデータを保存している。
これらのシステムレコードはYB-Masterを対象にRaftグループを組みレプリケーションすることで冗長性を実現している。 またシステムレコードはYB-Masterが管理するDocDBに保存される。
Authoritative source of tablet assignments to YB-TServers
YB-Masterは全てのテーブルとそれらをホストするYB-TServerの情報を保存している。
一般のクライアントではそれらの情報はクライアントからクエリレイヤなどを通して取得された上で、クライアントにメタデータを返し データアクセスが行なわれる。 一方でスマートクライアントではYB-Masterに保存されたメタデータを利用して特定のYB-TServerが保持するタブレットやキャッシュを利用 することが出来るため、データアクセス時のネットワークをまたぐ通信を減らすことができパフォーマンスを高めることができる。
Background operations
いくつかのオペレーションはUniverseのライフタイムを通してバックグラウンドで行なうことで、フォアグラウンドのRead/Writeに 影響を与えずに実行することが出来る。
Data placement and load balancing YB-Masterのリーダーは
CREATE TABLE時にタブレットの初期配置をYB-TServerをまたいで行なう。そのときにユーザー定義の データ配置制約を強制し均一な読み込みを保証する。 それに加えUniverseのライフタイム中のノード追加や障害が発生しても、負荷分散を継続しデータ配置の制約を自動的に適用する。Leader balancing 複数のYB-TServerに配置されたタブレットへのアクセスがUniverseをまたいで分散されることを保証している一方で、 YB-Masterは対象となるノード1間でそれぞれのノードが同じ数のtablet-peer leader2をもつことを保証する。
Rereplication of data on extended YB-TServer failure YB-Masterは全てのYB-TServerからハードビートシグナルを受け取ることでYB-TServerの死活監視を行なっている。 そしてYB-MasterはYB-TServerの異常を検知したときに、どれぐらいのあいだYB-TServerが異常であったかを追跡する。 異常であった時間が閾値を超えると、YB-Masterは障害中のYB-TServerに配置されていたタブレットを再配置するYB-TServerを探し、 レプリケーションを実行する。 レプリケーションはYB-Masterリーダーに抑制された状態で実行されるため、Universeのフォアグラウンドオペレーションには影響をおよぼさない。