YugabyteDBのドキュメントを全部読む Day2
前回からつづいてYugabyteDBのドキュメントを読んでいきます。
前回はArchitecture > Design goalsを読みました。 今回はArchitecture > Key Concepts > Universeを読みます。
また画像は同ドキュメントより引用しています。
Universe
YugabyteDBは耐久性とスケーラビリティを兼ねそなえた分散データベースを達成するために、Universe1と呼ばれるノードのグループを持っている。 Universeはビジネス要件やレイテンシの兼ね合いでシングルゾーン、単一リージョンマルチゾーン、マルチリージョン、同期・非同期レプリケーションなどを選択することが出来る。
UnivereはClusterと表現されることもある。
データの構成
Universeは一つ以上のネームスペースを持つことができ、またネームスペースは一つ以上のテーブルを持つことができる。 YugabyteDBではUniverse上に存在するノードにまたがって保持されるテーブルを設定に従って、シャーディングし、レプリケーション、ロードバランシングを行なう。
YugabyteDBはノードやディスク、ゾーンなどに発生した障害に自動で対応し、必要であればデータを新規に分散、レプリケーションを行なう。
- ネームスペースはYSQLではデータベースに対応し、ほかのDBにおけるネームスペースに対応する2。
- YCQLではキースペースに対応し、Cassandraのキースペースに対応している。
サービスコンポーネント
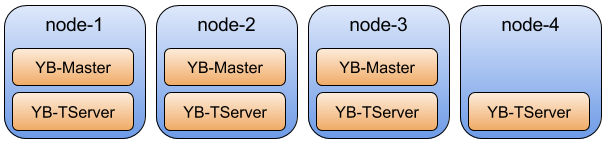
UniverseはYugabyteDB Tablet Server(YB-TServer)とYugabyteDB Master Server(YB-Master)の二つで構成されている。 YB-MasterとYB-TServerはRaftにより分散されており、高可用性を達成している。
- YB-Tserverはテーブルを始めとしたユーザーデータの保存、提供を担当する。
- YB-Masterはシステムのメタデータを管理し、システム全体のテーブルに対するDDLやメンテナンスの実行、ロードバランシングといったオペレーションを管理する。
UniverseとCluster
Universeは一つのプライマリクラスタとゼロ個以上のレプリカクラスタによって構成されている。
プライマリクラスタ
プライマリクラスタはRead/Write両方の実行と、プライマリクラスタ内のノード間の同期的なレプリケーションを担当する。
リードレプリカクラスタ
リードレプリカクラスタはRead処理のみを実行する。Write処理は自動的にプライマリクラスタにルーティングされる。 リードレプリカクラスタを利用することで、地理的に分散したデータに対する読み取りの遅延を小さくすることができる。 データはプライマリクラスタから非同期的にとりこまれる。これはRaftの書き込みには関与しないRaftオブザーバとして機能する。
- GoogleのCloud Spannerでも同様にUniverseと呼ばれている↩
- PostgreSQLではSchemaの裏側に存在するデータ構造↩