CMU Advanced Database Systems Spring2023とは
カーネギメロン大学(CMU)ではAdvanced Database Systemsという講義が開講されており、特に2023年1月始まりの講義です。 講義の内容はモダンなDBMSの内部実装を学んで行くコースとなっており、データベースの歴史を皮切りに OLAP DB、ストレージモデルやCompressionなどなど様々な実装を学べるそうです。 https://15721.courses.cs.cmu.edu/spring2023/
この講義はReading Assignmentがあり、その対象となる論文や書籍内容は一般に公開されています。(一部非公開)
この記事ではその第一回、History of Databasesの"What Goes Around Comes Around" を読んだ感想文となります。
CMU生にはさらにWhat "What Goes Around Comes Around... And Around"という2023年公開の最新版があるそうです。 おそらくドキュメント指向やKVS、グラフ指向やNewSQLなど様々な加筆があるのでしょう。読んでみたいですね。
論文を読んで
IMS、CODASYL時代からリレーショナルへの変遷をたどったことで後世においてより良いとして選ばれたものとそれへの反対、 新しい機能の提案とそれが市場に受け入れられるプロセス、そして複雑さとシンプルさのサイクルを学んだ。 おそらくこれらの変遷、市場との関わり方はデータベースのみならずあらゆることに適応できるんじゃないかと思う。
現在の比較的新しい技術であるNewSQLはもともと市場のelepahntであるGoogleにより生み出され、また
既存のRDBが抱えていたwriteスケールアウトへの課題からおそらく今後受容されるのではないかと思う。
またXMLで生まれたセミ構造化が比較的シンプルな現在のJSONやドキュメントDBに受け継がれたこと、また ビジネス側の素早い開発に対応したいというニーズの合致により現在の成功があるのでしょう。
一方でOracleのConverged Databaseの考え方は正しいと思える反面、RDBの起原であるシンプルさからは
遠ざかっているように感じる。XMLやCODASYLほど難しくなければ大丈夫なのだろうが、このまま機能を
膨らませ続けると……と不安にもなる。
この論文で言う複雑さはデータモデルの複雑さだから、様々なデータモデルを集めることは問題ではないのかもしれない。
What Goes Around Comes Around
Abstract
この論文はタイトルからわかるとおりデータベースの歴史についてまとめたもので、1960年代から2006年までの35年を9つの時代に分けて振り返っている。 35年の歴史の中でデータモデルは共通したアイデアが多く、たった数種類しか登場していない。
データベースの歴史を学ぶ重要性としてほとんどの研究者は歴史を学んでおらず、すでに否定されたアプローチを再発してしまうことがあるためである。 実際今(2006年当時)のXML時代は1970年代のCODASYLの「複雑さ」という失敗を繰り返している。
Introduction
データモデルの提案は1960年代から始まった。この論文では以下の9つの時代についてまとめている。
- 階層型(IMS): 1960年代後半から1970年代にかけて
- ネットワーク(CODASYL): 1970年代
- リレーショナル: 1970年代から1980年代前半にかけて
- エンティティ-リレーションシップ: 1970年代
- 拡張リレーショナル: 1980年代
- セマンティック: 1970年代後半から1980年代
- オブジェクト指向: 1980年代後半から1990年代前半
- オブジェクトリレーショナル: 1980年代後半から1990年代前半
- セミ構造化: 1990年代後半から現在(2006年当時)
階層型(IMS): 1960年代後半から1970年代にかけて
IMSは1968年にリリースされた階層型データモデルでレコードタイプの概念を持っていた。 レコードタイプとはデータ型に紐付いた名前のついたフィールドの集まりである。
それぞれのインスタンスのレコードタイプはレコードタイプによって指定されたデータの説明に従っており、 またいくつかの名前付きフィールドはどのレコードを指定しているのか明示していなければならない(Keyのようなもの)。
そしてレコードタイプは木構造を成している
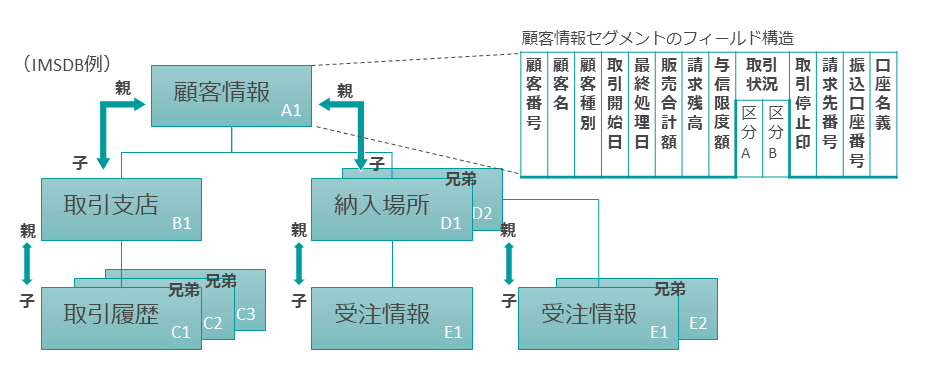
これらを満たす木構造データには2つの課題があり、は情報の重複と(ルート以外)親が必ず存在しなければ行けないことである。
コメント: 現代プログラミングでも情報の重複は同様の理由で忌諱されてますね。
IMSが階層型データを選んだのはデータ処理をシンプルにするためである。
IMSの操作言語DL/1は1レコードずつしか処理できず(record-at-a-time)、プログラマがクエリのアルゴリズムを記述しIMSが実行する方式を取っていた。
IMSは4つのストレージフォーマットがありいくつかはDL/1の実行に制限を与えた。 それはオペレーションのパフォーマンス劣化を防ぐためであったものの、DL/1のプログラムが正しく動くことを保証できないためデータの保存方法を 最適化することができなかった。
データベースアプリケーションがどんなチューニングが行われたかに関わらず物理レベルで動き続けることをデータの物理的独立性(physical data independence)と呼ぶ。
DBMSアプリケーションは通常一度に書かれるわけではないため重要である。新規プログラムが追加されるたびにチューニングの需要は変わり、
より良いDBMSのパフォーマンスはストレージの構成を変更することで達成される。
IMSはそれを一部制限した。
またアプリケーショの論理的要件は時間とともに変わり、ビジネスや法律などの要因で新しいレコードタイプが必要になったり、
特定のデータを異なるレコードタイプに移動する必要が出たりする。DL/1は論理的データベースとして定義されていたため
IMSではある程度のデータの論理的独立性(logical data independence)をサポートしていた。
コメント: ビジネスロジックが増えてもDBMSを使うアプリの機能を追加できないと困る
上で記載したIMSの課題を解決するためにIMSは異なる2つのデータベースからデータタイプを共通の値で"fused(joined)"する方法を提供した。
そのおかげで冗長性やデータの存在しないときなどに対応できるようになった。
このIMSの特徴から以下のレッスンを学ぶことができる。
データの物理的・論理的独立性は非常に望ましい
木構造データモデルはとても制限的
洗練された木構造データの論理的データ再構成は難しい
record-at-a-timeユーザーインターフェースはプログラマにマニュアルのクエリ最適化を強制し、それはしばしば難しい。
ネットワーク(CODASYL): 1970年代
CODASYL(Committie on Data Systems Languages)委員会は1969年にネットワークデータモデルのレポートをリリースした。 委員会は1971年、1973年とread-at-a-time型データ処理言語の仕様をリリースしており、アドホック型の委員会であった。
ネットワークデータモデルはそれぞれKeyを持ったレコードタイプの集まりから構成されており、木構造というよりはネットワーク構造になっている。
そのためIMSとは異なりレコードインスタンスは複数のownerを持つことができ、IMSが"fused"として提供していたデータ構造をより自然に表現できた。
ネットワークの点同士の対応関係(原文ではnamed arc)はCODASYLではsetと呼ばれているが数学的なsetとの関わりはない。
すべてのownerは0個以上のchildレコードタイプを持つことができ、要するに1-to-nの関係が成り立つ。
CODASYLのネットワークは複数の名前の付きレコードタイプと名前付きsetからなるグラフであり、そこには必ず一つ以上のentry pointが存在する。
entry pointとはいずれのsetのchildでもないレコードセットである。
このCODASYLのデータ構造はIMSのいくつかの問題を解決したものの、setが双方向関係(two-way relationship)しか示すことができず 三方向関係(three-way relationship)を表現する場合3つのsetが必要になり不自然な表現になってしまう。
コメント: 3つのFKを持つテーブルを作るときにjunction tableが3必要になるからってこと?
またCODASYLのデータアクセス言語はrecord-at-a-time方式を取っており、子レコードタイプのentry pointとなる親以外の親に到達したい場合、
entry pointのsetに属する子を探しその中から子につながる特定のsetを持つ親を探すという方法を取る。
CODASYLで提案されたデータアクセスの手法は複数あったものの、本質的にデータの物理的・論理的独立性を提供しなかった。
CODASYLではプログラマが最後にアプリケーションがアクセスしたレコード、最後にアクセスしたレコードのレコードタイプ、
そして最後にアクセスしたレコードのsetタイプを管理する必要がありCharlie Bachman(産業界のデータベース研究者)が
「四次元を航海するようだ」と表現下ほど難解であった。
加えてIMSがそれぞれのデータベースが独立して外部データソースからのバルクロードが可能だったに対し、 CODASYLはすべてのデータが一つの大きなネットワークであったため大きなデータを一度にロードする必要があり時間がかかった。 そしてCODASYLのデータベースが破損した場合すべてのデータをダンプから復元する必要があり、データの復旧に多くの時間がかかった。
このCODASYLの特性から以下のレッスンを学ぶことができる。
ネットワークは階層型に比べ柔軟であるが複雑でもある。
ネットワークの読み込みと復旧は階層型に比べ複雑である。
リレーショナル: 1970年代から1980年代前半にかけて
階層型とネットワーク型データベースを背景に1970年、Ted Coddはリレーショナルモデルを提案した。このデータモデルは データの独立性にフォーカスされている。この提案は以下の3つである。
データをシンプルに構造で保存する(テーブル)
データにはハイレベルなset-at-a-time DMLでアクセスする
物理ストレージへの提案は不要
シンプルなデータ構造にすることで論理的データの独立性を、ハイレベルなDMLでを提供することで物理的データの独立性を提供し、 物理ストレージの提案を不要とした。 またリレーショナルモデルの柔軟さはほとんどすべてのデータを表現可能というアドバンテージを実現した。
研究者を始めとしたリレーショナルデータベース推進派と産業界のDBMSユーザーによるCODASYL推進派で、
どちらのほうが優れているかという議論が行われた。
この議論が行われた頃にマイコンの大量生産と一般化により、OracleやINGRESなど多くの商用リレーショナルシスタムが台頭した。
一方で既存のネットワークモデルシステムは移植性が低くマイコンではあまり広がらなかった。しかし産業界が強いメインフレームでは
IMSやIDMSなどリレーショナルではないシステムが引き続き使われた。また現実的なデータマネジメントはメインフレームで行われた。
1984年にIBMがDB/2をメインフレーム向けにリリース。DB/2は容易に使うことができたため市場で大きな成功を収め、リレーショナルデータベースを
の今後を決定付けSQLはリレーショナル言語のデファクトとなった。
コメント: RDBが成功するのは必然のように思えるがIBMのDB/2がリリースされなければどのように展開していたのだろう
その後IBMはIMSのインターフェースとしてDL/1だけではなくSQLを対応する方針を取った。IMSの上にSQLを対応させるのは非常に難航した。
これらの経緯から以下のレッスンを学ぶことができる。
Set-at-a-time言語は物理的データの独立性を向上させるため、データモデルに関わらず優れている
論理的データ独立性はシンプルなデータモデルほど達成しやすい
技術的な議論は技術的な理由よりも市場の雄によって左右されることが多い
クエリオプティマイザはDBMSアプリケーションのプログラマによって書かれたrecord-at-a-timeのクエリより優れていた
エンティティ-リレーションシップ: 1970年代
Peter Chenは1970年代中盤にリレーショナルやCODASYL、階層型の大体としてエンティティ-リレーションシップ(E-R)データモデルを提案した。
この提案ではデータベースをエンティティのインスタンスの集合として捉え、いずれのエンティティもアトリビュートというエンティティの
特徴を定めるデータエレメントを持つと定義した。
E-Rデータモデルでは一つ以上のアトリビュートをユニークなデータ(Key)としてデザインし、エンティティ間でリレーションシップを持つと定義した。
データモデルとしてE-Rデータモデルが受け入れられることはなかった一方でデータベース(特にスキーマ)のデザインツールとして大きく成功した。 当時すでに第一から第四を含む複数の正規化が提案されていたものの、機能的依存関係(Functional Dependencies)などを前提としていた。 そのためデータベースアドミニストレータにとってはすぐに適用することが難しかった一方で、 E-Rデータモデルを使用した手法とツールは第三正規化を行ったテーブル群を提供できたため大きく成功した。
このE-Rデータモデルの経緯から
- 機能的依存関係の理解は多くの人々にとって難しい
という学びを得ることができる。
拡張リレーショナル: 1980年代
1980年代初頭頃からリレーションデータベースやクエリ言語の考えを拡張する形で様々論文が発表された。 その中で発表された考えの中で特に影響の大きかったものはGemというクエリ言語であり特徴は以下である。
Set-valued attributes
特定の値しか取らないアトリビュートに対して、そのようなデータ型を提供するAggregation (tuple-reference as a data type)
Foreign Keyで参照されたほかエンティティのタプルに対して、"cascated dot"記法による以下のようなアクセス方法を提供する。
Select Supply.SR.sno From Supply Where Supply.PT.pcolor = "red"
- Generalization
アトリビュートが共通する複数のエンティティがある時、共通部分を切り出したエンティティとそれを継承(inherit)するエンティティを作成できる。
Gemは様々な便利な機能を提供した一方でリレーショナルモデルのクエリ言語に比べて速度が不足した。
1980年代初頭リレーショナルモデルのベンダーではトランザクション処理のパフォーマンスとスケーラビリティに焦点を起き、
大規模なビジネスシーンで使われた一方拡張リレーショナルなアイデアが与えた影響は一部にとどまった。
そこから以下の学びを得ることができる。
- 大きなパフォーマンスの改善または機能的優位性がない限り、新しい機能は受け入れられない
セマンティック: 1970年代後半から1980年代
時をおなじくしてリレーショナルとは他の学派がリレーショナルデータモデルは意味的に貧弱であると主張し、 ポストリレーショナルデータモデルとしてセマンティックデータモデル(SDM)を提案した。
SDMはクラスと呼ばれる同じスキーマに従うレコードの集まりに焦点を当てている。SDMはGemのようにAggrigationやGeneralizationを実装し、 またSDMのGemeralizationでは複数のクラス同士で対応関係を持つアトリビュートや複数のエンティティからの継承(multiple inheritance)を提供した。 そしてSDMのクラスはクラス変数を持っていた。
ほとんどのSDMは非常に複雑であり、机上の提案で有ることが多かった。一部SDMデータベースを実装したものがあったが、そのときにはすでにSQLが デファクトと鳴っており、SQLとの互換性がないシステムは市場において成功を収めることは難しかった。
SDMは拡張リレーショナルと同様の問題を2つ抱えていた。一つはほとんどの機能がリレーショナルデータベースで再現可能であること。もう一つは 著名なベンダーはトランザクション処理の効率化に心血を注いでおり、あまり大きな影響を残すことがなかった。
オブジェクト指向: 1980年代後半から1990年代前半
1980年代半ばからオブジェクト指向DBMS(OODB)に関心が集まった。この流れはリレーショナルデータベースとC++をはじめとしたオブジェクト指向言語 との間のインピーダンスミスマッチに起因するものであった。
1970年末期、RDBでは独自の命名システム、データ型、クエリの結果を持ち、またプログラミング言語もそれらに対する独自のシステムを持っていた。
データベースとプログラミング言語がそれぞれにやり取りするための仕組みを提供する必要があった。
そのような状況に対応するためDBMSとプログラミング言語をより密結合させる機能を実装する流れができ、
特に永続的プログラミング言語(persistent programming language)というプログラミング言語の変数で
ディスクベースのデータをメモリに乗ったデータのように扱う方法などを提供する言語を実装しようとした。
しかしそのような1970年代の永続的プログラミング言語の取り組みはプログラミング言語の専門家には受け入れられず一般化することはなかった。
このような経緯とC++の興盛があり1980年半ばに永続的プログラミング言語が再度注目され、またオブジェクト指向データベース(OODB)の研究が
盛んになった。
多くのOODBではC++をデータモデルとしてサポートし、その結果C++のオブジェクトを永続化した。永続化C++はエンジニア市場に訴求するために
1. 問い合わせはC++オブジェクトを通して参照する、2. トランザクション管理を行わない、3. 従来のC++と競争できるランタイムを提供する、といった
要件を定めた。
コメント: ORMマッパーのようなプログラム側でよしなにするのではなくDBMSで対処しようとするのが実にデータベース脳
しかし以下のような理由からすべてのOODBベンダーは失敗した。
OODBベンダーはデータのロード、アンロード機能を提供したが多くの顧客はそれに大金を払うほどの価値を見出さなかった
スタンダードが存在せず、全てのOODBは互換性がなかった
永続化されたオブジェクトのなにかが変更された場合、それを使用するすべてのプログラムは再読込を必要とした
加えてOODBはトランザクション管理がなくビジネスデータを扱うには貧弱で、プログラムがデータベース上のすべてのデータにアクセスできる。 そしてCODASYL時代と同様record-at-a-timeのクエリしか提供しないといった理由から市場に浸透することはなかった。
これらのOODB時代から以下の教訓を得られる。
オブジェクトリレーショナル: 1980年代後半から1990年代前半
オブジェクトリレーショナル(OR)時代はINGRESで地理情報システム(GIS)を扱いたいというモチベーションから始まった。
地理的地点の情報は二次元情報でINGRESSのB-treeでは一次元アクセスしか実装されておらず、簡単なGIS検索をSQLで表現することが難しく
普通のB-treeで処理しようとすると非常に性能が悪かった。初期のRDBでは整数型、フロート型、文字列型と基本的なオペレータ、B-treeによる
データアクセスのみがサポートされていたが、GISをはじめとしたそれ以外のデータ型とアクセス方法を必要とする市場があった。
そのような状況に対応するためORはユーザー定義のデータ型、オペレータ、関数、そしてアクセスメソッドの機能をSQLエンジンに追加した。
その機能を搭載したプロトタイプとして1986年にPostgresが発表した。
またGISのような多次元インデックスに対応するためQuad treeやR-treeが提案され、高性能GIS DBMSを構築することができた。
時をおなじくして、Sybaseがストアドプロシージャを開発した。これによりアプリケーションとDBMSの間で処理を少ないやり取りに減らすことが
でき、アプリケーションのパフォーマンスを効率化することができた。
これらの機能に加えPostgresは継承、参照(reference)、集合、配列、といった機能を追加したことでオブジェクト指向RDBMSとなった。
当時PostgresはIlustraにより商用化され数年間は市場を探すことに苦労したものの、その後のインターネットの流行の波に乗り サイバースペースのデータベース(the data base for cyberspace)として成功を収めた。
Postgresによって発展したOR技術はOracleなどにも適用され、またXMLのサポートにも使われている(た)。一方でOR技術はスタンダードが存在 しないためビジネスでの仕様がはばかられた。
我々はこのPostgresとオブジェクトリレーショナルから以下の学びを得られた。
オブジェクトリレーショナルのメリットは以下の2つである
- データベースにコードをのせられる(またコードとデータの境界を曖昧にする)
- ユーザー定義アクセスメソッドの提供
- データベースにコードをのせられる(またコードとデータの境界を曖昧にする)
新しい技術を広げるにはスタンダードか大手によるゴリ押しが必須
セミ構造化: 1990年代後半から現在(2006年当時)
直近5年(2006年当時のため2000年ごろ)、セミ構造化データの研究の波が来ている。特にXMLを中心としたXMLSchemaやXQueryと行った 技術である。それぞれの研究の共通点として特に下記の2つがある。
Schema Last(データが先)
複雑なネットワーク指向データモデル(XMLデータモデル)
Schema Last
セミ構造化以前のデータモデルではデータをDBMSのに蓄積するためにはスキーマが必要であった。一方でセミ構造化データでは
スキーマ定義を後回し、または定義せずデータインスタンス自体が構造を説明する方式を取った。
自己説明型データを実現するためにはそれぞれのアトリビュートがメタデータを持つ必要がある。
一方でそのようなデータは同一データタイプのインスタンス同士を比較することが難しい。なぜなら同じオブジェクトの情報が
同じ表現をしていることとは限らないからである。このような状態をセマンティック異質性(semantic heterogeneity)と呼ぶ。
データは以下の4種類に分類することができる。
完全な構造化データ
いくらかのフィールド名を含む完全な構造化データ
セミ構造化データ
テキストデータ
Schema Lastアプローチを取れるのは3つ目のセミ構造化のみである。なぜなら1,2はORDBMSとして扱われるデータであり、4のテキストデータは 完全にスキーマが存在しないからである。 またそのようなデータは控えめな量であり、Schema lastデータベースはニッチなマーケットと言えるだろう。
コメント: 2023年現在、確かに筆頭ではないもののニッチと言うには大きめな需要だと考える
複雑なネットワーク指向データモデル(XMLデータモデル)
XMLデータモデルはDocument Type Definitions(DTDs)またはXMLSchemaにより記載されるデータで、DBMS研究者のコミュニティでは欠陥があると 考えられている。なぜならこれらの標準は今まで提案されたすべてのデータモデルの仕様を含み、十分複雑な仕様含むからである。
例えばXMLSchemaは以下のような特徴がある。
IMSのように階層化できる
CODASYLやGem、SDMのように参照できる
SDMのようにセット・アトリビュートを持てる
SDMのように他のレコードを継承できる
これらに加えXMLSchemaはDBMSコミュニティがその複雑さのために既存のデータモデルには用いなかった、 union type(一つのアトリビュートが複数のデータ型を取れる機能)などを実装している。
XMLSchema以上に複雑なデータモデルも過去には存在していた。これほど複雑なデータモデルについて考察することは難しいが、 以下の様なシナリオが考えられる。
XMLSchemaはその複雑さから失敗する
よりシンプルなXMLSchemaのデータ指向なサブセットが提案される
XMLSchemaはIMSやCODASYLと同様の問題を抱えながらも成功する
コメント: 2023年現在JSONは2番目のシナリオのもと十分に成功したと言える
セミ構造化データのサマリ
XMLデータモデルはその複数の機能からまとめることは難しいが、XMLは通信をまたいで連携するためのデータモデルとして成功しあらゆるシステムは XMLデータの送受信に備えることになるだろう。
コメント: 2023年現在ではJSONで置き換えられつつあるとはいえ、セミ構造化データが連携用データモデルとして成功したと言える
理由は簡単で他のデータフォーマットがファイアウォールを超えることができない一方で、XMLはシステム間の成約をこう得てプレーンテキストとして やり取りすることができるためである。
XML DBMSは(2006年)現在主流なDBMSと競争することのできるパフォーマンスのエンジンとなると思われるが、Schema Lastは限られた市場でのもの になるだろう。
次にXqueryは複数ベンダーのOR SQLシステムをマッピングできるサブセットとなるだろう。XqueryをUDFとして定義することは難しくないため、 既存のエンジンの上にXQuery関数をUDFとして定義することでSQLインターフェースの上に実装されるだろう。
コメント: 実際2023年現在に主流なDBMSであるOracle、MySQL、PostgreSQLはいずれもXqueryとXML機能を提供している
またXMLは時折セマンティック異質性(semantic heterogeneity)を解決すると考えられているがそのようなことはないだろう。
これらのセミ構造化データとXMLはから以下のレッスンが得られる。
まとめ(Full Circle)
このペーパーでは30年間のデータモデルの変遷を追って来たが、30年間で一周したと言えるだろう。
複雑なモデルで始まり、シンプルなデータ構造との対立、シンプルさの利点と受容とデータの独立性。
その後の実践的な機能の追加が提案と、XMLによる再びの複雑さである。
1980年代前半にCODASYLとリレーショナルの対立を経験したものはXMLのの成功を疑っている。 歴史と同じ過ちを繰り返さないためにはすでにその道をたどった人々の肩の上に乗ることが重要である。
it is always wise to stand on the shoulders of those who went before, rather than on their feet.
直近の20年(1980年から2000年にかけて)本質的に新しかったデータモデルのアイデアは
- データベース上のコード(オブジェクトリレーショナルから)
- Schema last(セミ構造化から)
のみであった。
注釈
- 「IMSデータ活用、近くで見るか、遠くで見るか? ~IMSデータ活用ソリューションとしてのDVMとCCDCを比較する」(https://www.imagazine.co.jp/ims-data-solution/)より↩