Column Sketchesというindex手法の論文を読みました
この記事の趣旨
前回と同様に CMU Advanced Databas Systems Spring2023のReading Assignmentとして出ている論文を 読んで行きます。最近論文を読めてなかったのですが、この記事 でモーベーションが上がったので再開しました。
ころころやり方を変えるのはよろしくないものの、モチベーションのために先の記事のやり方でやります。
今回はColumn Sketchという名前のIndex手法を提案した論文です。Lossy Compressionを採用した当手法がどのように、 高速で堅牢な検索を実現しているのかについて述べています。
Column Sketches: A Scan Accelerator for Rapid and Robust Predicate Evaluation
Brian Hentschel, Michael S. Kester, Stratos Idreos
著者について
Brain、Michael、Stratosのグループによる論文。いずれも機械学習とデータアクセスについて研究している。
問題意識
既存のindex手法ではそれぞれに得意/不得意があり多くのアクセスパターンに対応できる方法がなかった。 またデータ分析で用いられるような列指向ストレージに対応しているものが少なかった。
Column SketchはデータをLossy Compressionを使用してindexを作成する手法でこれらの問題を解決した。
手法
提案手法はデータを任意のbit長に変換し、bitで表わされたデータに対して初回の検索を行なうことで大幅に検索速度を 向上させた。
またこの手法は数値型のみではなく、varcharなどで表わされたカテゴリカルタイプを数値として扱うことで、データ分析に必要な データタイプに対応している。
提案手法は8bit数値型であれば以下のようなマッピングによって達成される。
- for x, y ∈ I8, S (x) ≠ S (y) ⇒ x ≠ y
- for x, y ∈ I8, S (x) < S (y) ⇒ x < y
以下の図は8bitデータに対してWHERE x < 90がどのようにindex作成され評価されるかの例である。
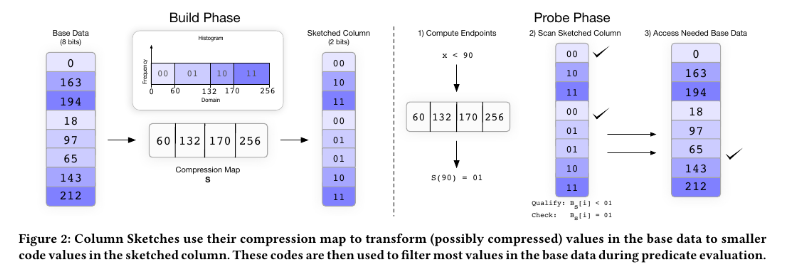
index作成段階では数値をレンジベースで任意の個数のbitに圧縮する。 そして評価時には90を含むデータより大きい値をすべて取得し、90を含むレンジに対しては個別に評価を行なう。
感想
読んでいる段階では数値型のみに対応したindexであれば、B-treeで十分ではないかと思ったものの 読み進めていくと限定的ながらも文字型にも対応していて、分析用途では必要な機能が備わっているなと思った。 全文テキスト検索のような用途には応用が難しそうで、銀の弾丸はないなと感じた。
作業時間
- read
- 27 min
- 27 min
- author
- 32 min
- 5 min
- summary
- 58 min
- 26 min
論文以外への感想
今回採用した論文の読み方をやってみた 思ったのは事前に1時間で読んでまとめるぞと決めたことで随分集中して論文を読めました。 あと今まで論文を原文で読まなきゃという個人的な使命感があったのですが、翻訳することで随分効率があがったので 今後は翻訳してしまおうと思いました。
Readableは文末のrea-dableのような表記や翻訳されない部分(おそらく数式を含む文章?)があるものの、 フォーマットが維持されているため原文と照しあわせながら読めば非常に効率がよかったです。 毎日論文読むなら正直買いです。
毎日論文読みたいので課金しました。がんばるぞ!