KubeCon NA 2024: Database DevOps: CD for Stateful Applicationsのセッションレポート
この記事は以下アドベントカレンダー14日目の記事です。
Database DevOps: CD for Stateful Applications セッションレポート
セッション概要:
セッションスライド
- https://static.sched.com/hosted_files/kccncna2024/86/Harness-Portworx%20Kubecon%202024.pdf
- この記事内の画像は全てこのスライドより引用しています。
セッション動画
このレポートでは、KubeCon + CloudNativeCon North America 2024 のセッション「Database DevOps: CD for Stateful Applications」の内容をまとめたもので、DatabaseのDevOpsとステートフルアプリケーションの継続的デリバリについてです。
データベースCDの課題と解決策
セッションでは、データパイプラインのデータテストをデリバリパイプラインに統合することの重要性が強調されていました。従来、データベースのテストは、BIツールなどを用いたカスタマイズされた方法で行われることが多かったようですが、最も信頼性の高いテスト方法は、新旧バージョンで同じデータに対してテストを実行することだとスピーカーは主張していました。そして、Kubernetesはこのようなテストを大幅に簡略化できるとのことでした。この主張は、データベースの変更がアプリケーション全体に及ぼす影響を正確に把握し、本番環境へのデプロイ前に潜在的な問題を早期に発見するために非常に重要です。
Kubernetesによるデータベース運用の進化
セッションで紹介されたアーキテクチャの進化は、Kubernetesがデータベース運用にもたらす利点を明確に示していました。初期のアーキテクチャでは、アプリケーション、データベース、インフラストラクチャの変更が個別に管理されていましたが、発展したアーキテクチャでは、これらが統合されたCI/CDパイプラインで管理されています。この統合により、アプリケーション、データベース、インフラストラクチャの変更をE2Eでテストできるようになり、本番環境へのデプロイリスクを大幅に軽減できます。
このアーキテクチャの進化は、マイクロサービスアーキテクチャやクラウドネイティブ開発との親和性が高いと言えます。マイクロサービスでは、個々のサービスが独立してデプロイされるため、データベースの変更が他のサービスに及ぼす影響を正確に把握することが重要です。Kubernetesはこのような複雑な依存関係を管理し、安全なデプロイを実現するための強力なプラットフォームを提供します。
デモのオーバービュー
セッションでは、具体的なスキーママイグレーションのシナリオを例に、ダウンタイムゼロでのデータベース変更を実現する方法が紹介されていました。WarehouseテーブルのLocationカラムの衝突問題を解決するために、CityとStateカラムを追加し、Locationカラムとの同期をトリガーで実現する方法は、実務で非常に役立つアプローチです。この手法は、データベースの変更によるアプリケーションへの影響を最小限に抑え、ユーザー体験を損なうことなくシステムを進化させることを可能にします。
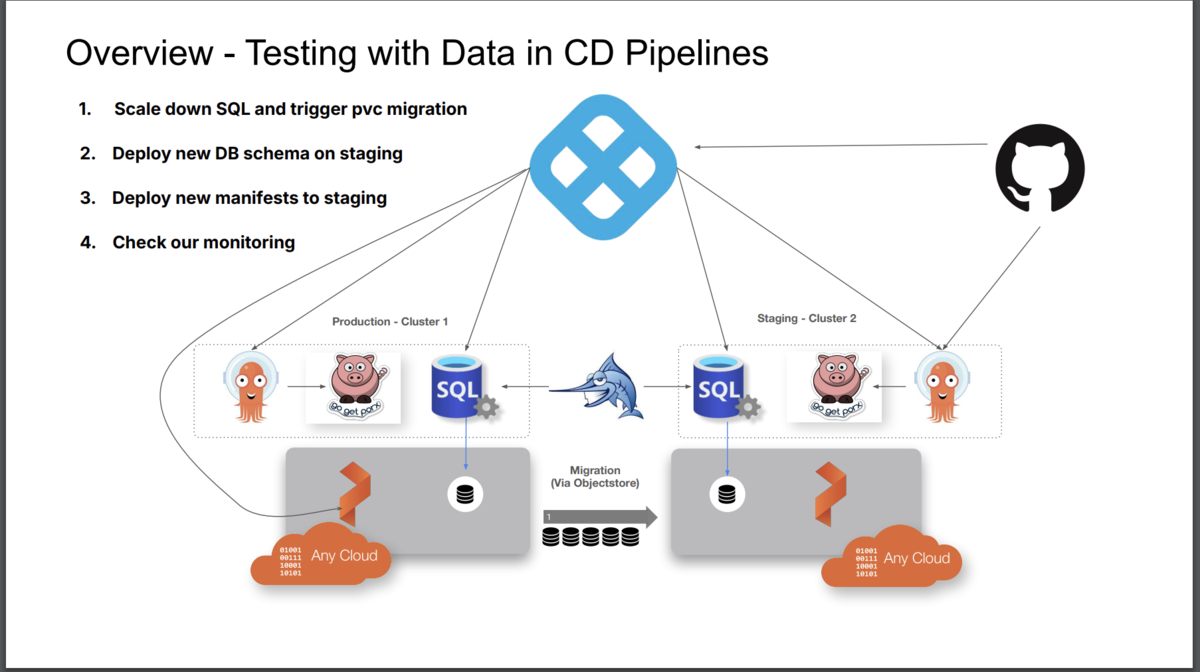

個人的にはこのようなユースケースのテストシナリオは複雑になることが多いと考えていたため、自動化を行うには相当のカスタマイズが必要になると思っていたので、この後のデモの手軽さには非常に驚かされました。
デモのハイライトとHarnessの活用
このセッションはデモが全体のほとんどを閉めています。デモ開始時点のリンクがブログ記事の中盤にあるので、デモ部分だけでもご覧になることを強く推奨します。
セッションのデモでは、Harnessというツールが使用され、変更プロセスとロールバック手順が分かりやすく可視化されていました。Harnessは、GitLab CI/CDやGitHub ActionsのようなUIを提供し、各ステップの成功/失敗を容易に確認できる点が優れていると感じました。特に、ArgoCDとの連携によるデータベースとアプリケーションの協調動作は、複雑なデプロイプロセスを簡素化する上で非常に効果的です。
デモで紹介された、望ましい状態になっていないことを確認し、変更を加えるプロセスは、実践的な知見を提供していました。また、データベースの変更セットの一部として事前にロールバック手順を定義しておくことは、本番環境での予期せぬ問題発生時に迅速な対応を可能にするベストプラクティスと言えるでしょう。LiquibaseやFlywayなどのツールはこのような機能を提供しており、データベースDevOpsの実践において不可欠です。 HarnessではデータベースのDevOpsをアプリケーション、インフラストラクチャー込みで実現しており、非常に理想的なツールのように見えました。一方でこのセッションのスピーカーのひとりはHarnes.ioのエンジニアであるため、ポジショントークや見せたい部分しか見せていないことが十分考えられるので全てを鵜呑みにするのは危険です。 それを差し引いても興味深いデモだったので、セッションで紹介された技術スタックを検証してみたいと思っています。
まとめ
このセッションは、Kubernetesとツールを活用することで、データベースの変更を安全かつ効率的に行う方法を示していました。E2Eテスト、ダウンタイムゼロのスキーママイグレーション、そしてロールバック手順の自動化は、データベースDevOpsを実現するための重要な要素です。これらの手法を適切に組み合わせることで、開発速度を向上させながら、システムの安定性と信頼性を維持することが可能になります。
しかし、ここで紹介された手法は全ての状況に適用できるわけではありません。例えば、大規模なデータベースや複雑なトランザクション処理を行うシステムでは、ダウンタイムゼロのマイグレーションが困難な場合があります。そのようなケースでは、段階的なロールアウトやカナリアリリースなどの手法を検討する必要があります. また、ツールの導入や運用にはコストがかかるため、組織の規模やリソースに合わせて適切なツールを選択することが重要です。
今後のデータベース運用においては、自動化と可観測性をさらに強化し、自己修復機能を備えた自律的なデータベース運用を目指していくことが重要だと考えます。Kubernetesやクラウドネイティブ技術は、この目標を実現するための基盤となるでしょう。
またこのセッションを見るまで、個人的にDatabase on KubernetesはKubernetesを利用している組織でマネージドデータベースのコストを安くしたい場合や、データを自分たちのコントロールできる場所におきたい時に利用する選択肢と思っていました。 しかしデータベースをKubenetesにデプロイすることでアプリケーションと密接に結合したテストを簡単に行えることがわかり、データベースの運用コストさえ許容できれば、他のメリットがなくてもデータベースをKubernetesで運用するのは十分ありなのではないかと意見が変わりました。 今後は単なるデータベースのホスティング環境としてのKubernetes以外の部分にも注目していきたいです。